
In 1897 Vilfredo Pareto, an Italian economist, identified that 80% of the wealth was owned by 20% of the population in his country. The observation that wealth was distributed in that way led Dr Juran, a management consultant, to (mis)label this phenomenon as the Pareto principle (commonly known as the 80-20 rule). Dr Juran applied this principle outside the field of economics.
When applied to commerce, the Pareto principle means that about 20% of your efforts generates 80% of the results. Or think of it in terms of a small number of clients making up the majority of your business, or a small number of blog articles generating the most traffic. Learning to focus on that 20% is the key to effective time management. This phenomenon equally applies to computer system caching.
In computing terms, a cache is a collection of temporary data that will be required to be accessed in the future, and can be retrieved extremely quickly. The data stored within a cache may be a simple reproduction of information held elsewhere or it may have been the results of a previous computation. Where data stored in the cache is requested, this is known as a cache hit. The advantage of a cache hit is that the request will be served considerably faster. The flipside, a cache miss, occurs when information has to be recalculated or retrieved from its original location, consuming more system resources and slower access. If 20% of data is accessed 80% of the time, and a system can be utilized which reduces the cost and time of obtaining that 20%, system performance will dramatically improve. Fine tuning a system to improve the cache hit rate speeds up overall system performance.
Caches are employed in a variety of different ways. For example, we see caches being used to store items in memory, to disk, and to a database. Caches are also frequently used to service DNS requests, as well as distributed caching where caches are used to to spread across different networked hosts.
We have already highlighted notable open source web caches in our article entitled Best Free and Open Source Linux Web Caches. The purpose of this article is to identify open source software which caches data in other situations.
The ratings chart below captures our verdict. Only free and open source software is eligible for inclusion. Hopefully, there will be something of interest here for anyone who deploys applications that require predictable, low-latency, random access to data with high sustained throughput.
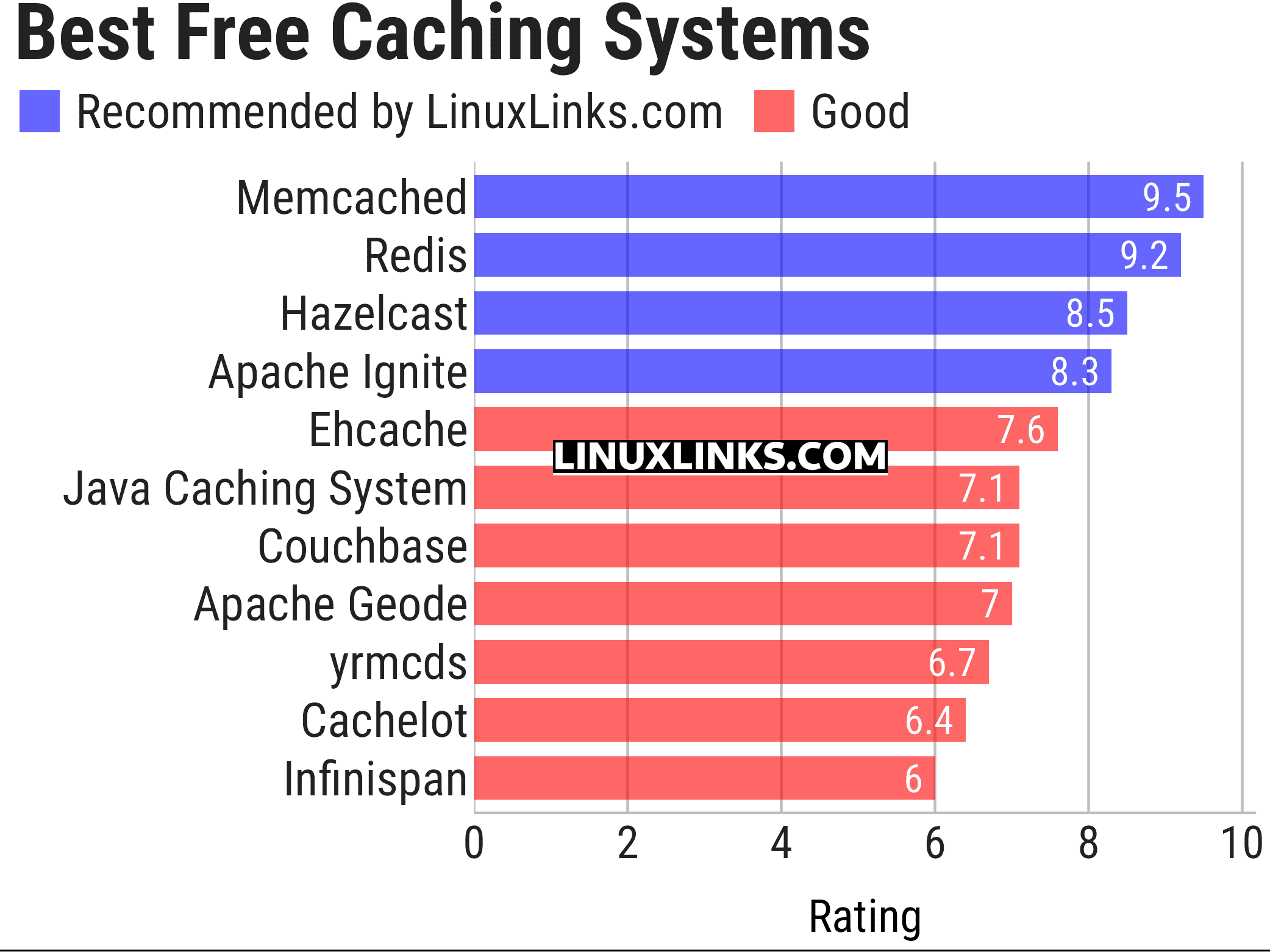
Click the links in the table below to learn more about each program.
| Caching Systems | |
|---|---|
| Memcached | High-performance distributed memory object caching system |
| Redis | Persistent key-value database with network interface |
| Hazelcast | Distributed in-memory data store and computation platform |
| Apache Ignite | Distributed database, caching and processing platform |
| Ehcache | Standards based pure Java in-process cache |
| Java Caching System | Distributed caching system written in Java |
| Couchbase | Distributed key-value database management system |
| Apache Geode | Distributed, in-memory data management platform |
| yrmcds | LRU cache library and key-value server |
| Cachelot | Memory object caching system with master/slave replication |
| Infinispan | Distributed, in-memory database and data grid |
This article has been updated to reflect the changes outlined in our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |