
Big Data is an all-inclusive term that refers to data sets so large and complex that they need to be processed by specially designed hardware and software tools. The data sets are typically of the order of tera or exabytes in size. These data sets are created from a diverse range of sources: sensors that gather climate information, publicly available information such as magazines, newspapers, articles. Other examples where big data is generated include purchase transaction records, web logs, medical records, military surveillance, video and image archives, and large-scale e-commerce.
In the past decade, the world of computing has been transformed. Oceans of data are now not only found in large companies; even some small companies accumulate terabytes of data. Organisations of all sizes therefore have an increased need to handle large amounts of data, and relational databases are stretched to their limits in terms of scalability. We need a solution which helps to achieve scaling and higher availability.
Serving systems are unable to cope with bulk load massive immutable data sets without affecting serving performance. Performance is impaired as valuable resource is sucked away by index creation and modification as CPU and memory resources are shared with request serving.
A solution is a key value store. This is one of the non-relation database models, such as graph, document-oriented database models. Key value stores allow the application to store its data in a schema-less way. The data can be stored in a datatype of a programming language or an object. This removes the need for a fixed data model. Key value stores refers to a general concept of database where entities (values) are indexed using a unique key.
This feature highlights the finest open source key value stores. Hopefully, there will be something of interest for anyone who needs to store millions of data records, to help in statistical or real-time analysis. Here’s our verdict captured in a legendary LinuxLinks-style ratings chart.
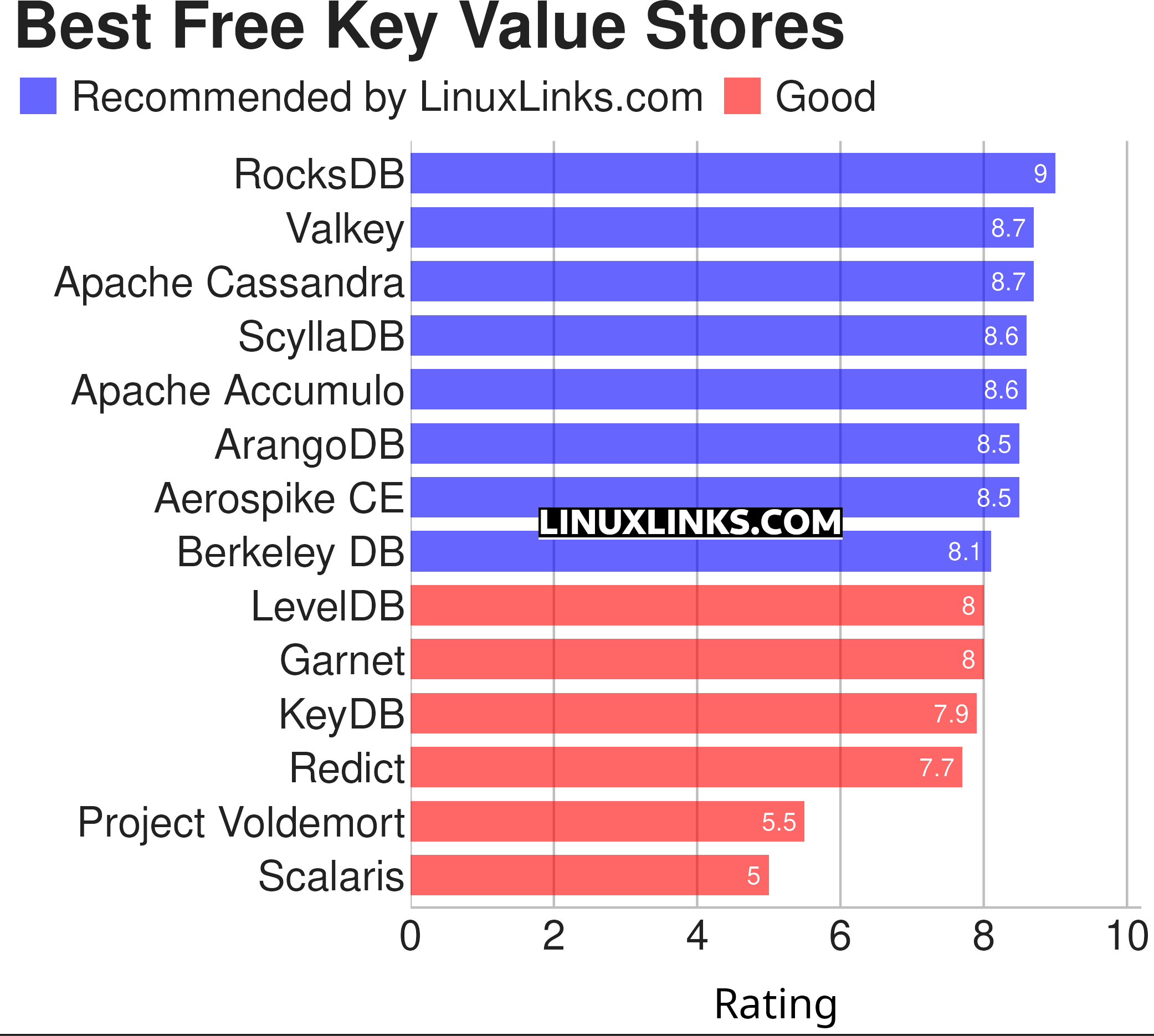
Let’s explore the 14 key value stores at hand. For each title we have compiled its own portal page, a full description with an in-depth analysis of its features, together with links to relevant resources.
| Key Value Stores | |
|---|---|
| RocksDB | Persistent key-value store for flash and RAM Storage |
| Valkey | High-performance data structure server |
| Apache Cassandra | Distributed database management system |
| ScyllaDB | Real-time big data database |
| Apache Accumulo | Based on Google's BigTable design |
| ArangoDB | Native multi-model database |
| Aerospike CE | Real-time NoSQL database and key-value store |
| Berkeley DB | Family of open source, embeddable databases |
| LevelDB | Fast and lightweight key/value database library by Google |
| Garnet | Remote cache-store |
| KeyDB | High performance fork of Redis |
| Redict | Distributed key/value store |
| Project Voldemort | Distributed data store |
| Scalaris | Distributed transactional key-value store |
This article has been revamped in line with our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |
No Redis?
We decided to remove Redis from the roundup following its change of license.
That’s what I love about open source software. There are quite a few good forks of Redis that are in the spirit of open source.