In Operation
When the software is installed, point your web browser to http://localhost:7860 or http://127.0.0.1:7860. You’ll see the web user interface.
At the top is a dropdown headed Stable Diffusion checkpoint. Models, sometimes called checkpoint files, are pre-trained Stable Diffusion weights intended for generating general or a particular genre of images. The install script downloaded v1.5, but we also recommend downloading the v2.1 model (v2-1_768-ema-pruned.safetensors). Move the file to the stable-diffusion-webui/models/Stable-diffusion folder. You can then select that model from the dropdown.
The first tab is labelled txt2img. Probably the first thing to try is to enter a prompt which can be a maximum of 75 characters. This prompt text tells the model what to generate. Once you’ve chosen the prompt click the Generate button.
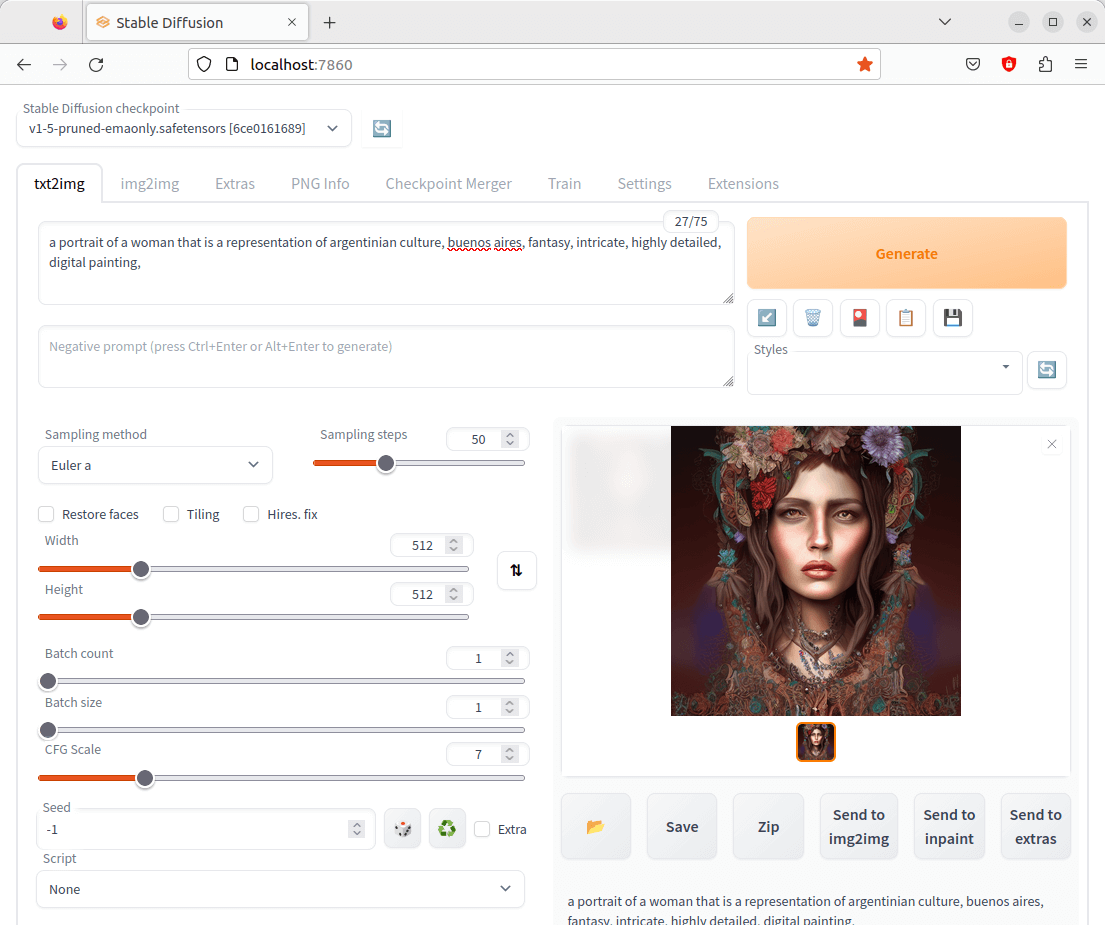
The model has generated an image based on our prompt. There’s support for Composable-Diffusion, a way to use multiple prompts at once, and you can specify parts of text that the model should pay more attention to.
Below the prompt is a box for negative prompts. They are the opposites of a prompt; they allow the user to tell the model what not to generate. Negative prompts often eliminate unwanted details like mangled hands or too many fingers or out of focus and blurry images.
The next tab is img2img which generates a new image from an input image using Stable Diffusion.
The Extras tab is also very useful. For example, you can upscale and/or apply face restoration to any images, not only images created by Stable Diffusion. It’s like Upscayl but on steroids. There are a wide range of upscalers to try, and both GFPGAN and CodeFormer face restoration tools are supported. The ability to apply different strengths to the face recognition is really useful.
Summary
Stable Diffusion web UI offers a dazzling array of features. There are so many highlights that it’s impossible to summarise them adequately in a short review. Support for hypernetworks, Loras, DeepDanbooru integration, xformers, batch processing, a checkpoint merger are just a few of the things we love. The user interface is good although a bit more work on the design and layout would be great.
It’s a shame that installing models with Stable Diffusion’s web UI is a manual affair. InvokeAI’s model manager is a really good idea as it makes it simple to quickly experiment with a variety of different models. We recommend you download the Stable Diffusion v2.1 model, in part because the model has the power to render non-standard resolutions. That helps you do all kinds of awesome new things, like work with extreme aspect ratios that give you beautiful vistas and epic widescreen imagery.
Stable Diffusion web UI has attracted a stonking 50,000+ GitHub stars.
Website: github.com/AUTOMATIC1111/stable-diffusion-webui
Support:
Developer: AUTOMATIC1111
License: GNU Affero General Public License v3.0
Stable Diffusion web UI is written in Python. Learn Python with our recommended free books and free tutorials.
![]() For other useful open source apps that use machine learning/deep learning, we’ve compiled this roundup.
For other useful open source apps that use machine learning/deep learning, we’ve compiled this roundup.
Pages in this article:
Page 1 – Introduction and Installation
Page 2 – In Operation and Summary
The project is fast approaching 100,000 GitHub stars
I often take little notice about how many stars a project has, although I do sit up and take notice when the project has more than 10k. So having nearly 100k is very impressive.
Why are GitHub stars generally not a useful metric? Because there are a number of reasons why people give a star, and often not because of the quality of the project.
1) Many people give a star to a project that they haven’t even tried and may never will. The star acts as a bookmark, so that it’s a project that potentially interests them.
2) Even if they have actually tried the project, many people who star a project don’t use it regularly. If they stop using it, they rarely destar.
3) There’s definitely fake stars given, given by bots.
When I’m reviewing music software I never even consider the number of GitHub stars; it’s totally irrelevant to my evaluation process.