
Speech is an increasingly popular method of interacting with electronic devices such as computers, phones, tablets, and televisions. Speech is probabilistic, and speech engines are never 100% accurate. But technological advances have meant speech recognition engines offer better accuracy in understanding speech. The better the accuracy, the more likely customers will engage with this method of control. And, according to a study by Stanford University, the University of Washington and Chinese search giant Baidu, smartphone speech is three times quicker than typing a search query into a screen interface.
Witness the rise of intelligent personal assistants, such as Siri for Apple, Cortana for Microsoft, and Mycroft for Linux. The assistants use voice queries and a natural language user interface to attempt to answer questions, make recommendations, and perform actions without the requirement of keyboard input. And the popularity of speech to control devices is testament to dedicated products that have dropped in large quantities such as Amazon Echo. Speech recognition is also used in smart watches, household appliances, and in-car assistants. In-car applications have lots of mileage (excuse the pun). Some of the in-car applications include navigation, asking for weather forecasts, finding out the traffic situation ahead, and controlling elements of the car, such as the sunroof, windows, and music player.
The key challenge for developing speech recognition software, whether it’s used in a computer or another device, is that human speech is extremely complex. The software has to cope with varied speech patterns, and individuals’ accents. And speech is a dynamic process without clearly distinguished parts. Fortunately, technical advancements have meant it’s easier to create speech recognition tools. Powerful tools like machine learning and artificial intelligence, coupled with improved speech algorithms, have altered the way these tools are developed. You don’t need phoneme dictionaries. Instead, speech engines can employ deep learning techniques to cope with the complexities of human speech.
There are some very exciting open source speech recognition toolkits available. These toolkits are meant to be the foundation to build a speech recognition engine.
This article highlights the best open source speech recognition software for Linux. The rating chart summarizes our verdict.
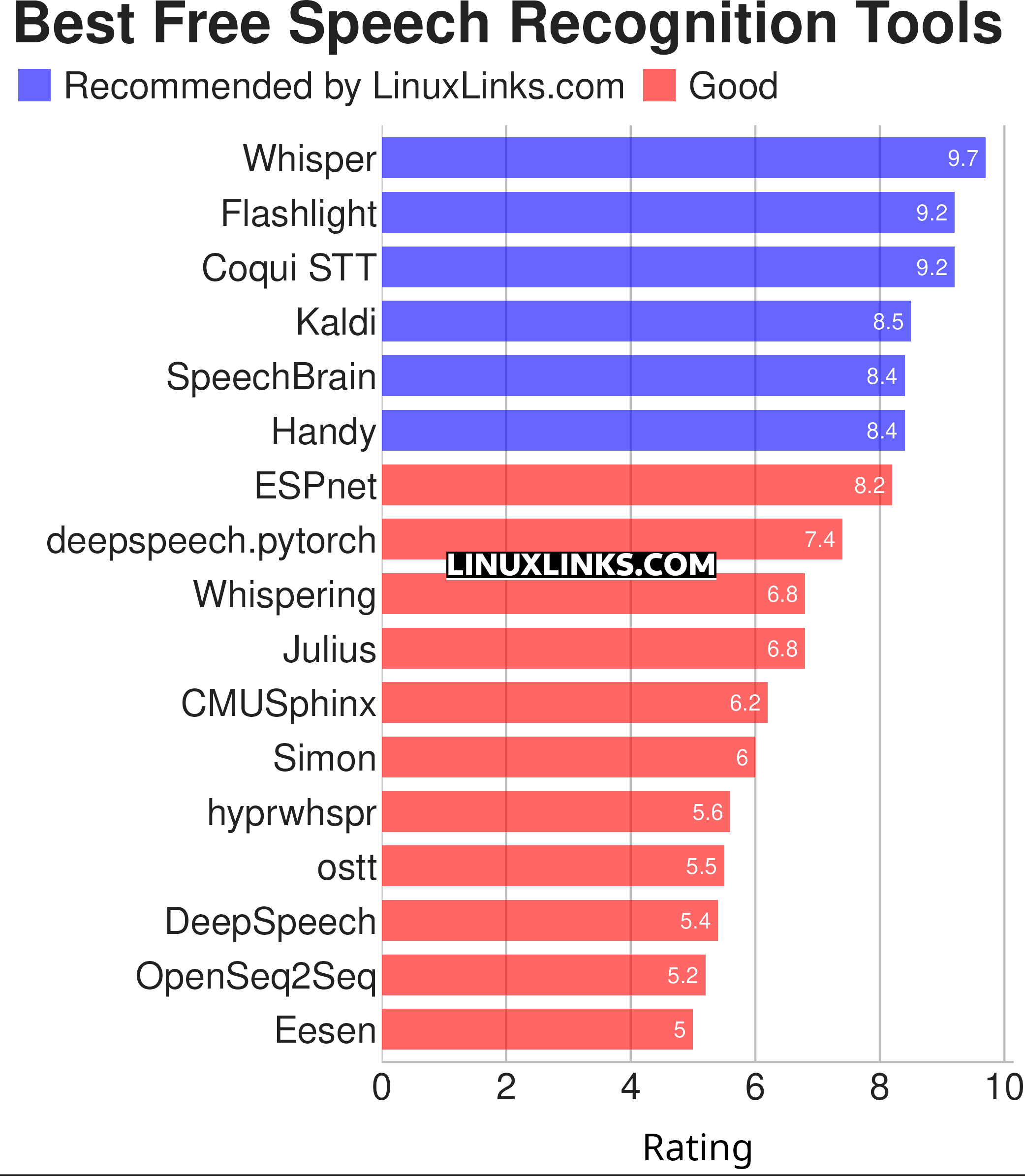
Let’s explore the 17 free speech recognition tools at hand. For each title we have compiled its own portal page with a full description and an in-depth analysis of its features.
| Speech Recognition Tools | |
|---|---|
| Whisper | Automatic speech recognition (system trained on 680,000 hours of data |
| Flashlight | Fast, flexible machine learning library written entirely in C++. |
| Coqui STT | Deep-learning toolkit for training and deploying speech-to-text models |
| Kaldi | C++ toolkit designed for speech recognition researchers. |
| SpeechBrain | All-in-one conversational AI toolkit based on PyTorch |
| Handy | Offline speech-to-text application |
| ESPnet | End-to-End speech processing toolkit |
| deepspeech.pytorch | Implementation of DeepSpeech2 using Baidu Warp-CTC. |
| Whispering | Transcription application with global speech-to-text functionality |
| Julius | Two-pass large vocabulary continuous speech recognition engine |
| CMUSphinx | Speech recognition system for mobile and server applications |
| Simon | Flexible speech recognition software |
| hyprwhspr | Native speech-to-text designed for Arch / Omarchy |
| ostt | Open Speech-to-Text |
| DeepSpeech | TensorFlow implementation of Baidu's DeepSpeech architecture. |
| OpenSeq2Seq | TensorFlow-based toolkit for sequence-to-sequence models |
| Eesen | End-to-End Speech Recognition |
This article has been updated to reflect the changes outlined in our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |
What is really wrong with the license terms of HTK?
This clause is particularly damning:
2.2 The Licensed Software either in whole or in part can not be distributed or sub-licensed to any third party in any form.
…and nothing else matters…
Sadly my machine doesn’t have sufficient RAM on my graphics card to experiment with DeepSpeech. Any recommendations for a good GPU that works well with DeepSpeech?
Thanks for the comprehensive info regarding the open source tools. From the perspective of a visually impaired person, what I would like to know is which of these would be most suitable (now or in near future) for dictating to get text that could go into documents, e-mail, etc. Is that Simon?
Yes, Simon is very good for what you’re looking for. Most of the other open source speech recognition tools are not really aimed at a desktop user e.g. they are for academic research etc.
Is there any speech to text tool like Dragon Nat in linux? I work as a translator and I have it on windows but I wonder if there is something like that out there.
Baidu is required by Chinese laws to act, as and when demanded, as an arm of the Chinese Communist Party. Not sure I would trust a tool created by them.
I think you are jumping on the Hauwei bandwagon with absolutely no justification.
A few of the open source programs here are using speech recognition models based on Baidu DeepSpeech2. But the model is an approach, not a means of capturing data or doing anything else nefarious.
What concerns are you raising? The source code of the programs here (DeepSpeech etc) are open source, so you can see exactly what they are doing.
I think the so-called “Voice of Reason of Reason” is actually foolish. Baidu and Hauwei are separate and different companies and therefore the Hauwei bandwagon is irrelevant. The CPC is a relevant threat.
Open Source is in itself is not a guarantee of safety. There are and have been plenty of nefarious open source programs. There are and have been plenty of open source bugs persisting for many years before remediation. Who is examining the code? The “Voice of Reason?”
Hard to take someone calling themselves “The Fool” seriously…
Conflating bugs with nasties. You certainly sound foolish, The Fool.
completely agree
This account is solely made for saying yes to other accounts called “john”
LinuxLinks doesn’t have accounts
Could Android speech recognition be ported to Linux desktop packages, since android is open source?
Update your web site! Simon is not in my package list and the links got to “application Simon not found” Using Mint 21.1.
It really doesn’t matter if a program is not in your distro’s package list.
But we have updated the URL.
Is the list regularly updated? The page says May 2023 but the comments show you’ve made updates to the URLs earlier this year
This article is due an update. Likely to happen fairly soon. URL changes don’t constitute an update.
Looking forward to it. I think the software has grown drastically since the last update and it’d be nice to have some structure around the available options.
Can you hurry up the update? When will it be done?