
In Operation
Web browser
We can access our newly created virtual environment with the command:
$ source .venv/bin/activate
Let’s now launch the Mimic 3 server with the command:
(.venv) $ mimic3-server
You’ll see output like this:
INFO:mimic3_http.__main__:Starting web server [2022-11-14 08:43:48 +0000] [8449] [INFO] Running on http://0.0.0.0:59125 (CTRL + C to quit) INFO:hypercorn.error:Running on http://0.0.0.0:59125 (CTRL + C to quit)
We’ve highlighted the section of the output showing us where to point our web browser.
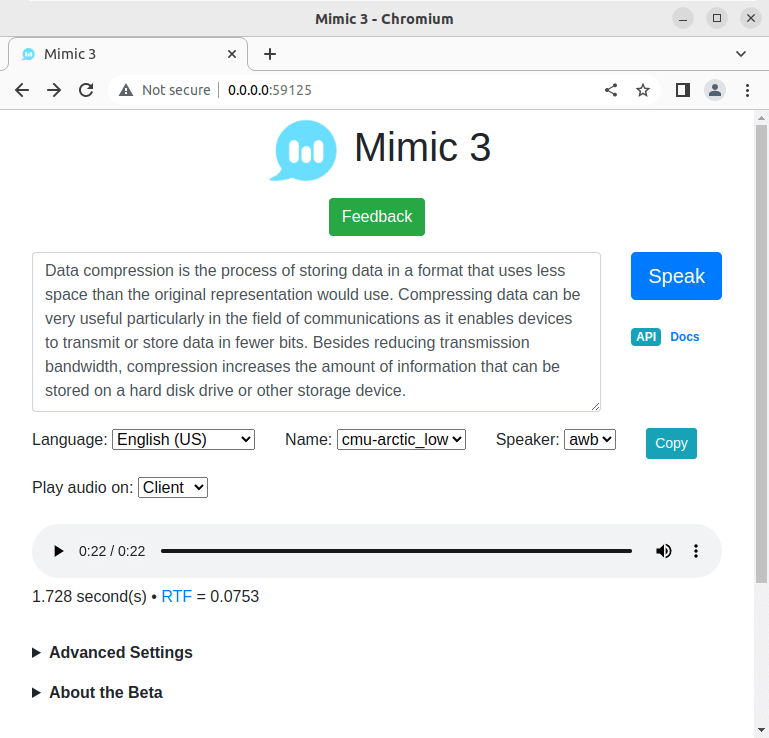
The image above shows the 22 second clip took only 1.728 seconds to be generated. You can accelerate the processing if you have a GPU that supports CUDA.
We can listen to the output or download it as a WAV file. Over 25 languages are available including English (US and UK), German, Spanish, Italian, Dutch, and Chinese.
Here are a couple of WAV examples (US and UK).
The software supports speech synthesis markup language, an XML-based markup language for assisting the generation of synthetic speech in Web and other applications. This lets you insert pauses, change the volume, speaking rate, and voice.
What else does the software offer?
- Custom word pronunciations.
- Over 100 pre-trained voiced.
- Run multi-speaker models
Summary
If you want a text to speech engine that works entirely offline on inexpensive hardware (such as the Raspberry Pi), Mimic 3 gets our recommendation.
We’ve only shown the software running as a web server. It’s also possible to use Mimic 3 from the command line or in a screen-reader.
Website: github.com/MycroftAI/mimic3
Support: Documentation
Developer: Mycroft
License: GNU Affero General Public License v3.0
Mimic 3 is written in Python. Learn Python with our recommended free books and free tutorials.
Pages in this article:
Page 1 – Introduction / Installation
Page 2 – In Operation / Summary
Related Software
| Speech Tools | |
|---|---|
| Piper | Fast, local neural text to speech system |
| Tortoise | Multi-voice text-to-speech system trained with an emphasis on quality |
| Coqui TTS | Offers pretrained models in more than 1,100 different languages |
| Bark | Transformer-based text-to-audio model. |
| Dia | 1.6B parameter text to speech model |
| Festival | General multi-lingual speech synthesis system |
| PraatSpeechAnalyser | Software for speech analysis and synthesis |
| Speech Note | Speech to Text, Text to Speech and Machine Translation |
| Mimic 3 | Lightweight Text to Speech engine |
| OrcaScreenReader | Scriptable screen reader |
| MeloTTS | High-quality multi-lingual text-to-speech library |
| Parler-TTS | Lightweight text-to-speech (TTS) model |
| Flite | Small, fast run time text to speech synthesis engine |
| RHVoice | Gives the visually impaired a synthesis voice with their screen reader |
| eSpeak NG | Continuation of the eSpeak project |
| eSpeak | Speech synthesizer using a formant synthesis method |
| Orpheus-TTS-FastAPI | High-performance self-hosted text-to-speech server |
| Gespeaker | GTK-based frontend for eSpeak |
| VoiceGen | Simple text-to-speech application |
| Glate | Google Translator and Text To Speech Service |
Read our verdict in the software roundup.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Discovered a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |
Please read our Comment Policy before commenting.
I am impressed by this. Thank you