
Last Updated on March 19, 2024
In Operation
The image below shows Llama 2’s response to our instruction to tell me about Linux.

If you’re interested in how long it took to generate the above response we can use the --verbose flag. Issue the command $ ollama run llama2 --verbose. Repeat the instruction for the model to tell us about Linux.
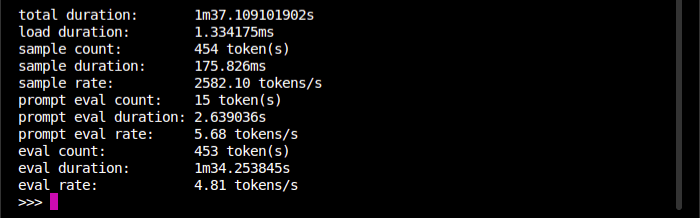
As you can see, it took around 97 seconds to generate the response. That’s slooooooooooooooooow.
The PC has an Intel i5-12400 CPU with 32GB of RAM together with a mid-range dedicated NVIDIA graphics card. The reason why responses are slow is because Ollama currently doesn’t support GPU processing under Linux. The developer has indicated this will be rectified in a future release.
Pages in this article:
Page 1 – Introduction
Page 2 – Installation
Page 3 – In Operation
Page 4 – Summary
Please read our Comment Policy before commenting.