
In Operation
There are various ways of using Audiocraft. We’ve chosen to demonstrate the software using gradio.
In the audiocraft directory, we launch the gradio interface with the command:
$ python app.py
Now we point our web browser to http://127.0.0.1:7860
There are four different models available. The most interesting is Melody, a music generation model capable of generating music based on text and melody inputs. When using the melody model you can provide a reference audio file from which a broad melody will be extracted. The model will then try to follow both the description and melody provided.
In other words, you provide the software with an audio file, and some text descriptions e.g. “lofi slow bpm electro chill with organic samples”, and the deep learning model will generate music for you based on the descriptions and the extracted melody. Sounds cool? It is!
There are a couple of reference audio files available in the assets sub-directory: bach.mp3 and bolero_ravel.mp3 but you can obviously use other audio files that you own.
In the interface, we’ve entered a text description in the input text field, and chosen the bach.mp3 file for the “condition on a melody”. We’ll use the melody model.
There are other parameters we can change such as the duration of the generated clip. Once satisfied, click the submit button.
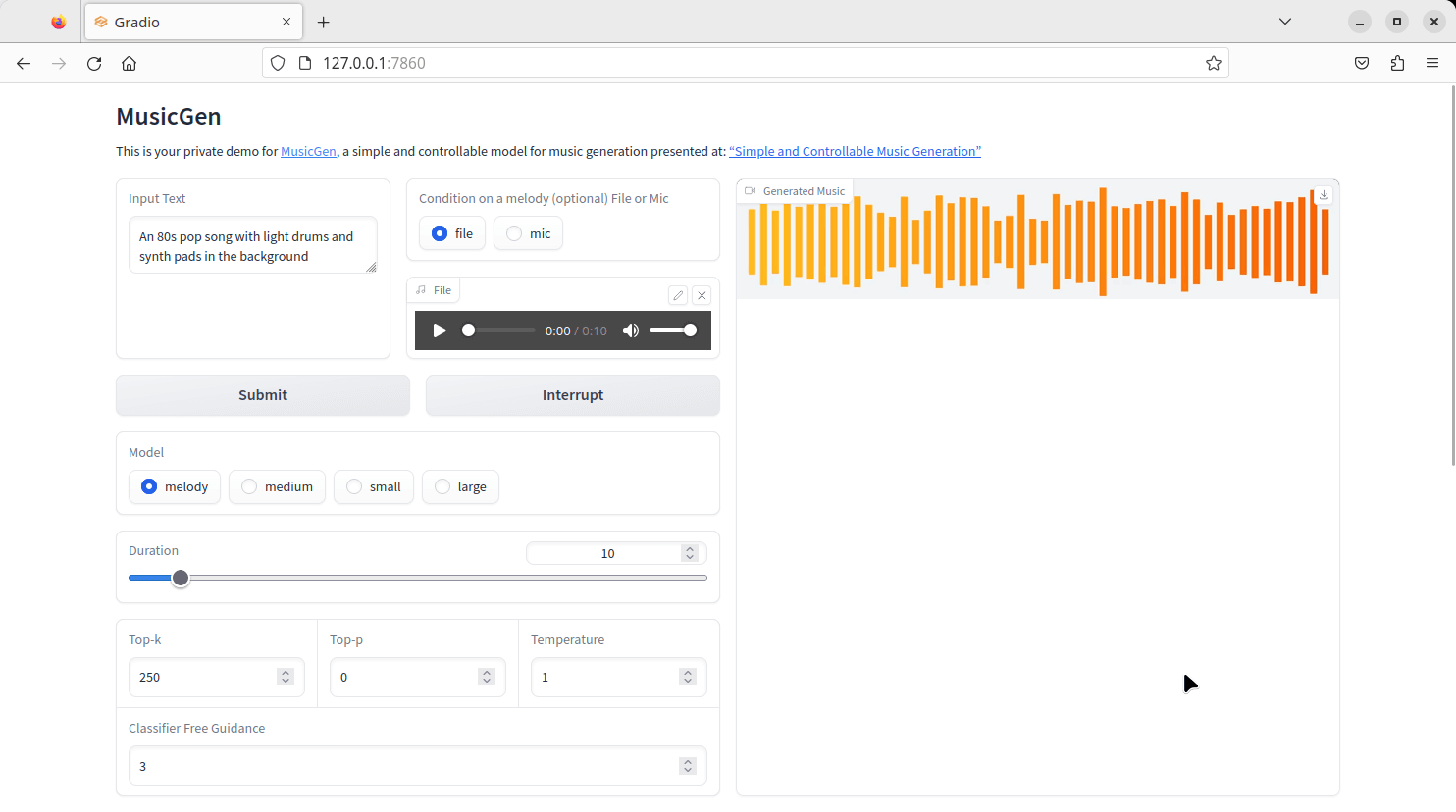
Here’s a generated mp4 audio file of 10 second duration.
The software lets you create audio files up to 30 seconds. The very first time you use a model, the software automatically downloads it for you. The models take up a fair chunk of hard disk space. The small, melody, medium and large models take up 1.1GB, 3.9GB, 3.0GB and 6.8GB disk space respectively. They are saved to ~/.cache/huggingface/hub/
The small, medium, and large models use text inputs only.
According to the project’s GitHub, Audiocraft will not run without a dedicated GPU. That’s out-of-date information, as the software will run on the CPU if an NVIDIA dedicated GPU is not detected (of course, it’ll run slowly). And the project’s GitHub says that you’ll need a GPU with 16GB of memory to generate long sequences, and if you have less than that, you’ll only be able to generate short sequences or revert to the small model (which doesn’t have melody to music.
However, we tested the software using a GeForce RTX 3060 Ti with only 8GB of VRAM and it is able to produce 30 second clips using the melody model with no issues. The clip below uses Ravel’s Bolero as the melody with text description “A cheerful country song with acoustic guitars”.
This 30 second clip took 39.6 seconds to be generated.
The 8GB of VRAM was not sufficient to use the large model even with a very short duration clip.
Pages in this article:
Page 1 – Introduction and Installation
Page 2 – In Operation
Page 3 – Summary
Thanks for the article. This is one of the best deep learning tools I’ve tried although it’s dog slow on my AMD CPU.
It’s like Stable Diffusion but for audio.
What irks me is the large RAM requirements. Fortunately I’ll be getting a GeForce RTX 4060 Ti so this will have enough RAM.