Optical Character Recognition (OCR) is the conversion of scanned images of handwritten, typewritten or printed text into searchable, editable documents. OCR software is able to recognise the difference between characters and images, and between characters themselves.
This article highlights OCR powered screen-capture tools to capture information instead of images. We only feature open source software here.
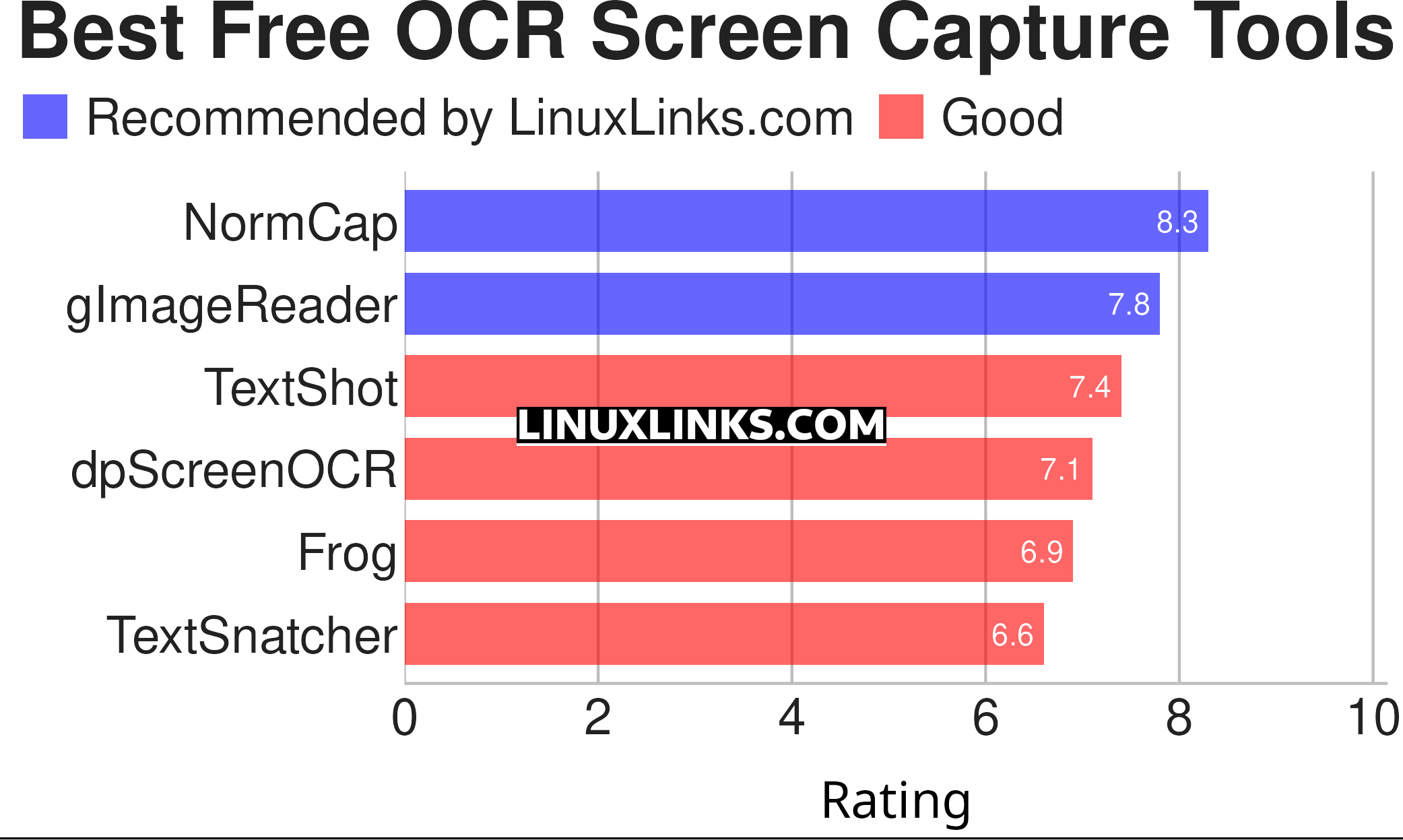
Here’s our verdict of the tools succinctly summarized in a LinuxLinks styled ratings chart.
The tools features in this article perform text recognition offline using the respected OCR framework Tesseract. For general OCR tools, please check out this roundup.
Let’s explore the 6 OCR screen capture tools at hand. For each title we have compiled its own portal page, a full description with an in-depth analysis of its features, a screenshot of the software in action, together with links to relevant resources.
| OCR Screen Capture Tools | |
|---|---|
| NormCap | OCR-powered screen-capture tool to capture information instead of images |
| gImageReader | Simple Gtk/Qt front-end to Tesseract |
| TextShot | Python tool for grabbing text via screenshot |
| dpScreenOCR | Powered by Tesseract, it supports more than 100 languages |
| Frog | Intuitive text extraction tool (OCR) for GNOME |
| TextSnatcher | Perform OCR operations in seconds |
This article has been revamped in line with our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |